среда, 28 апреля 2010 г.
вторник, 27 апреля 2010 г.
Менеджер запущенных приложений 1С
Иногда возникает ситуация, когда необходимо завершить работу какого-либо процесса 1С, но, если пользоваться стандартным диспетчером задач, то есть риск убить совсем не то.
Решить эту проблему призван Task manager 1C.
Программа показывает с какой базой работает процесс, также отображает список файлов, используемых процессом, список подгруженных модулей (dll) и заголовок окна программы.
Пути не определяются для серверных баз 8.х.
При работе программы используется приложение Handle, разработчик Mark Russinovich., поэтому при первом запуске необходимо согласится с условиями его использования, иначе определение путей к базам данных будет невозможным.
Для работы необходим установленный Microsoft .NET Framework 3.5.
Ссылка на Инфостарт
Решить эту проблему призван Task manager 1C.
Программа показывает с какой базой работает процесс, также отображает список файлов, используемых процессом, список подгруженных модулей (dll) и заголовок окна программы.
Пути не определяются для серверных баз 8.х.
При работе программы используется приложение Handle, разработчик Mark Russinovich., поэтому при первом запуске необходимо согласится с условиями его использования, иначе определение путей к базам данных будет невозможным.
Для работы необходим установленный Microsoft .NET Framework 3.5.
Ссылка на Инфостарт
понедельник, 26 апреля 2010 г.
LaTeX в блоге
На сайте советы.блогспот.ком нашел хорошую статью о том, как можно вставлять формулы в формате LaTeX на HTML-страницу. Для сообщений blogspot, как вы видите, это тоже подходит.
Вот так, например, работает первый способ:
Вот так, например, работает первый способ:
(a + b)^2 = a^2 + 2ab + b^2
Всё, что может понадобиться
Недавно я начал преподавать программирование. На самом деле говоря "преподавать программирование" это я так шучу. Слишком уж громко и пафосно это звучит. На самом деле просто я решил поделиться своими знаниями с одним человеком.
Вначале я подумал:
- Черт возьми! Программирование настолько огромная и сложная область знания, что совершенно непонятно с чего начать. Как же быть? Может, быть стоит начинать с двоичной системы (и разных систем счисления), ведь это основа работы компьютера (есть сигнал/нет сигнала). Или, может быть нужно внимательно рассмотреть аппаратную часть, познакомиться с принципом работы процессора? А возможно это должен быть какой-то язык и его синтаксис, чтобы можно было сразу приводить примеры и учить базовые алгоритмы? А, может быть вообще взять какой-нибудь визуальный редактор вроде Delphi, так как с помощью его можно быстро создавать маленькие, но полностью функциональные приложения?
Отчаявшись я сделал самый простой выбор, и решил начать с того с чего начинал я сам: с базового представлении об алгоритме и самых банальных блок-схем.
Через пару часов, когда мы разобрались как построить блок-схему, как представить задачу в виде последовательности действий и условий, как детализировать, я сказал:
- Пожалуй, это все, что может тебе пригодиться. На самом деле в этом и заключается все программирование и теперь у тебя есть все, что нужно.
И только на следующий день я понял, что в этом и был ответ на мой вопрос о том, что самое главноев танке в программировании. Ни синтаксис языка, ни понимание каких-то особенных вещей и технологий, ни двоичная система не имеют никакого значения, когда нет умения представить задачу и решение как алгоритм, как последовательность действий.
Хорошими друзьями алгоритма я бы назвал глубокое понимание парадигмы языка на котором пишешь и гибкий ум, позволяющий "догадываться" о новых вещах. Вот, пожалуй и все.
P.S.: Алгоритмы алгоритмами, но язык нам все-таки понадобится. И это будет C++ несмотря на то, что я сам его почти не знаю. Мы уже купили толстую книгу с названием "Базовый курс" и теперь будем учиться вместе.
Вначале я подумал:
- Черт возьми! Программирование настолько огромная и сложная область знания, что совершенно непонятно с чего начать. Как же быть? Может, быть стоит начинать с двоичной системы (и разных систем счисления), ведь это основа работы компьютера (есть сигнал/нет сигнала). Или, может быть нужно внимательно рассмотреть аппаратную часть, познакомиться с принципом работы процессора? А возможно это должен быть какой-то язык и его синтаксис, чтобы можно было сразу приводить примеры и учить базовые алгоритмы? А, может быть вообще взять какой-нибудь визуальный редактор вроде Delphi, так как с помощью его можно быстро создавать маленькие, но полностью функциональные приложения?
Отчаявшись я сделал самый простой выбор, и решил начать с того с чего начинал я сам: с базового представлении об алгоритме и самых банальных блок-схем.
Через пару часов, когда мы разобрались как построить блок-схему, как представить задачу в виде последовательности действий и условий, как детализировать, я сказал:
- Пожалуй, это все, что может тебе пригодиться. На самом деле в этом и заключается все программирование и теперь у тебя есть все, что нужно.
И только на следующий день я понял, что в этом и был ответ на мой вопрос о том, что самое главное
Хорошими друзьями алгоритма я бы назвал глубокое понимание парадигмы языка на котором пишешь и гибкий ум, позволяющий "догадываться" о новых вещах. Вот, пожалуй и все.
P.S.: Алгоритмы алгоритмами, но язык нам все-таки понадобится. И это будет C++ несмотря на то, что я сам его почти не знаю. Мы уже купили толстую книгу с названием "Базовый курс" и теперь будем учиться вместе.
пятница, 23 апреля 2010 г.
Виртуализация сервера приложений 1С с аппаратным ключом
Интересная статья на ITLand (от рассылки с которого я никак не могу отписаться!) о виртуализации и HASP.
http://itband.ru/2010/04/hyper-v1c/
http://itband.ru/2010/04/hyper-v1c/
четверг, 22 апреля 2010 г.
Microsoft Visual Studio 2010 и TFS 2010
В Киеве прошел запуск Visual Studio 2010. Ну, что можно сказать... За что я люблю Microsoft-овские сборища, так это за то, что там хорошо кормят и кофе бесплатно. ;-)
Это, как вы понимаете, шутка. А теперь серьезно.
Лично я был на серии докладов о VS и TFS (большой зал) и меня очень удивило, насколько сама Microsoft и ее продукты agile-ready. Надеюсь, они скоро выложат видео-запись, а пока скажу, что в самом начале серии докладов они сказали: "Сегодня не будет показано ни одного слайда. Мы прямо перед вами "в живую" отработаем один спринт (второй в проекте, если быть точным)". Обещание было сдержано - слайдов не было. Они действительно отработали одну scrum-итерацию распределив между собой роли (заказчик, скрам-мастер, pm, архитектор, разработчик, qa), полноценно от UserStory's до тестирования, демо и ретроспективы. Конечно, было много "домашних заготовок", вся инфраструктура уже была развернута и задачи были не сложными, но все же это было интересно и очень удивительно для меня. Да, глюки тоже были. ;-)
О самой VS. Что можно сказать. Это монстр. Нет. Это МОНСТР! Оно, как вы догадываетесь, интегрируется со всем чем можно и полноценно использует развернутую ms-инфраструктуру. О разных новых фичах можно рассказывать долго, но лучше вы почитайте обзоры, а я расскажу о том, что мне особенно понравилось.
Первое - это архитектурный контроль. Архитектор может построить некую диаграмму объектов проекта, где в качестве объектов могут выступать классы, модули, библиотеки и пр. И установить между ними связи. При вызове функции архитектурного контроля VS проверяет насколько существующий код соответствует диаграмме. Например, если у вас есть UI, который обращается к классу DBIntreface, который в свою очередь должен работать с БД, то построив диаграмму связей вы сразу же можете обнаружить где разработчик напрямую из UI дергает БД в обход DBIntreface, и указать ему на ошибку.
Второе, что очень запомнилось это "Центр тестирования". Интересный продукт, позволяющий проводить автоматическое и ручное тестирование приложений. Удобные инструменты, плюс опять-таки интеграция. Тест-кейсы с привязкой к юерз-сториз и все-такое.
Это была положительная сторона. О слабых моментах и негативе писать не буду, потому что, те, кто реально будет работать с Visual Studio 2010 найдут их сами, а общие о том, что "продукты MS слишком "толстые", что "нормально интегрируются только с другими продуктами MS" и т.д. и так все знают.
Конечно, доклады от Microsoft теперь все меньше похожи на доклады для технических специалистов, а скорее напоминают театрализованное представление, но в целом от продукта впечатление приятное, а главное, что я теперь как-то глубже и нагляднее представляю себе scrum. Вот уж чего не ожидал! =)
Это, как вы понимаете, шутка. А теперь серьезно.
Лично я был на серии докладов о VS и TFS (большой зал) и меня очень удивило, насколько сама Microsoft и ее продукты agile-ready. Надеюсь, они скоро выложат видео-запись, а пока скажу, что в самом начале серии докладов они сказали: "Сегодня не будет показано ни одного слайда. Мы прямо перед вами "в живую" отработаем один спринт (второй в проекте, если быть точным)". Обещание было сдержано - слайдов не было. Они действительно отработали одну scrum-итерацию распределив между собой роли (заказчик, скрам-мастер, pm, архитектор, разработчик, qa), полноценно от UserStory's до тестирования, демо и ретроспективы. Конечно, было много "домашних заготовок", вся инфраструктура уже была развернута и задачи были не сложными, но все же это было интересно и очень удивительно для меня. Да, глюки тоже были. ;-)
О самой VS. Что можно сказать. Это монстр. Нет. Это МОНСТР! Оно, как вы догадываетесь, интегрируется со всем чем можно и полноценно использует развернутую ms-инфраструктуру. О разных новых фичах можно рассказывать долго, но лучше вы почитайте обзоры, а я расскажу о том, что мне особенно понравилось.
Первое - это архитектурный контроль. Архитектор может построить некую диаграмму объектов проекта, где в качестве объектов могут выступать классы, модули, библиотеки и пр. И установить между ними связи. При вызове функции архитектурного контроля VS проверяет насколько существующий код соответствует диаграмме. Например, если у вас есть UI, который обращается к классу DBIntreface, который в свою очередь должен работать с БД, то построив диаграмму связей вы сразу же можете обнаружить где разработчик напрямую из UI дергает БД в обход DBIntreface, и указать ему на ошибку.
Второе, что очень запомнилось это "Центр тестирования". Интересный продукт, позволяющий проводить автоматическое и ручное тестирование приложений. Удобные инструменты, плюс опять-таки интеграция. Тест-кейсы с привязкой к юерз-сториз и все-такое.
Это была положительная сторона. О слабых моментах и негативе писать не буду, потому что, те, кто реально будет работать с Visual Studio 2010 найдут их сами, а общие о том, что "продукты MS слишком "толстые", что "нормально интегрируются только с другими продуктами MS" и т.д. и так все знают.
Конечно, доклады от Microsoft теперь все меньше похожи на доклады для технических специалистов, а скорее напоминают театрализованное представление, но в целом от продукта впечатление приятное, а главное, что я теперь как-то глубже и нагляднее представляю себе scrum. Вот уж чего не ожидал! =)
среда, 21 апреля 2010 г.
Волшебство n &= (n - 1);
Как всегда уважаемый Александр радует интересными вопросами. На этот раз это формализованное доказательство того, что следующая функция вернет количество единиц в числе переведенном в двоичную систему:
Т.е. фактически количество итераций цикла, равно количеству единичных (не нулевых) бит.
Хоть я и не математик, но попробуем внимательнее взглянуть на код...
int bitcount (unsigned int n) {
int count = 0 ;
while (n) {
count++ ;
n &= (n - 1) ;
}
return count ;
}
Т.е. фактически количество итераций цикла, равно количеству единичных (не нулевых) бит.
Хоть я и не математик, но попробуем внимательнее взглянуть на код...
Выполнение цикла будет прервано когда n станет равным нулю. Я считаю что формула
n &= (n - 1);
вызванная в цикле, убирает из n единицы (в двоичном представлении) до тех пор пока их совсем не останется.
Попробую доказать.
Для начала рассмотрим операцию n-1. Что будет происходить с числом в двоичном представлении? При вычитании единицы с числом в двоичном виде произойдет следующее: первый с правого края единичный бит будет обнулен, а предшествующие ему нули инвертированы. Вот так:
xx...xx100...00 - 1 = xx...xx011...11
где x -произвольные биты в левой части числа.
Это можно доказать следующим образом (если это нужно). Любое число A можно представить в виде:
А = bx*2x+bx-1*2x-1+...+b1*21+b0*20
где x - порядок бита в двоичном представлении числа,
а bx - сам бит в позиции x.
Значит и единицу можно представить следующим образом:
1=(1*20)=(1*21-1*20)=(1*22-1*21-1*20)...
Предположим, что b0=1, тогда:
A - 1 = (bx*2x+bx-1*2x-1+...+b1*21+1*20) - (1*20) = (bx*2x+bx-1*2x-1+...+b1*21+0*20)
Т.е. мы видим, что на место b0 подставился ноль, т.е. первый единичный бит справа был обнулен. (желтым я подсветил части выражения, которые взаимоуничтожаются из за разности знаков)
Если же первый единичный бит справа это b1 то можно сделать другую подстановку:
A - 1 = (bx*2x+bx-1*2x-1+...+1*21+0*20) - (1*21-1*20) = (bx*2x+bx-1*2x-1+...+1*21+0*20) - 1*21 + 1*20 = (bx*2x+bx-1*2x-1+...+0*21+1*20+0*20) = (bx*2x+bx-1*2x-1+...+0*21+1*20)
Теперь в позиции b1 ноль, зато в позиции b0 - единица.
Для предположения, когда первый единичный бит это b2:
A - 1 = (bx*2x+bx-1*2x-1+...+1*22+0*21+0*20) - (1*22-1*21-1*20) = (bx*2x+bx-1*2x-1+...+1*22+0*21+0*20) - 1*22+1*21+1*20 = (bx*2x+bx-1*2x-1+...+0*22+1*21+1*20)
И так далее и тому подобное.
Не знаю, считаются ли мои корявые рассуждения доказательством у настоящих математиков, но отсюда во-всяком случае понятно что происходит: в битовом представлении числа самая правая единица превращается в ноль, а все остальное за ней превращается в единицы.
Следующая операция это побитовый И.
Что произойдет с числами А и B когда с ним будет произведена побитовая операция И, если мы знаем, что:
1. B = A - 1, а значит, что
2. До бита с номером Y эти числа совпадают.
3. Бит с номером Y - самая правая единица в числе A, за которым идут нули.
4. Сам бит с номером Y в числе A равен единице, а в B равен нулю и
5. далее в числе A все последующие символы равны нулю, а в B - единице.
Очевидно, что часть числа ДО бита с номером Y останется неизменной, так как a&a=a.
Бит с номером Y будет обнулен и так же будут обнулены все последующие за ним, так как там один из операндов равен нулю.
Т.е. мы видим, что в результате этой операции самый правый единичный бит в байте превратился в ноль.
Мы сможем повторять эту операцию и результат не будет равен нулю до тех пор, пока последний единичный бит не станет нулевым. Очевидно, что количество итераций и будет равно количеству единиц в числе.
Извините, если мое описание немного сумбурное, буду благодарен за подсказки о том "как правильно".
n &= (n - 1);
вызванная в цикле, убирает из n единицы (в двоичном представлении) до тех пор пока их совсем не останется.
Попробую доказать.
Для начала рассмотрим операцию n-1. Что будет происходить с числом в двоичном представлении? При вычитании единицы с числом в двоичном виде произойдет следующее: первый с правого края единичный бит будет обнулен, а предшествующие ему нули инвертированы. Вот так:
xx...xx100...00 - 1 = xx...xx011...11
где x -произвольные биты в левой части числа.
Это можно доказать следующим образом (если это нужно). Любое число A можно представить в виде:
А = bx*2x+bx-1*2x-1+...+b1*21+b0*20
где x - порядок бита в двоичном представлении числа,
а bx - сам бит в позиции x.
Значит и единицу можно представить следующим образом:
1=(1*20)=(1*21-1*20)=(1*22-1*21-1*20)...
Предположим, что b0=1, тогда:
A - 1 = (bx*2x+bx-1*2x-1+...+b1*21+1*20) - (1*20) = (bx*2x+bx-1*2x-1+...+b1*21+0*20)
Т.е. мы видим, что на место b0 подставился ноль, т.е. первый единичный бит справа был обнулен. (желтым я подсветил части выражения, которые взаимоуничтожаются из за разности знаков)
Если же первый единичный бит справа это b1 то можно сделать другую подстановку:
A - 1 = (bx*2x+bx-1*2x-1+...+1*21+0*20) - (1*21-1*20) = (bx*2x+bx-1*2x-1+...+1*21+0*20) - 1*21 + 1*20 = (bx*2x+bx-1*2x-1+...+0*21+1*20+0*20) = (bx*2x+bx-1*2x-1+...+0*21+1*20)
Теперь в позиции b1 ноль, зато в позиции b0 - единица.
Для предположения, когда первый единичный бит это b2:
A - 1 = (bx*2x+bx-1*2x-1+...+1*22+0*21+0*20) - (1*22-1*21-1*20) = (bx*2x+bx-1*2x-1+...+1*22+0*21+0*20) - 1*22+1*21+1*20 = (bx*2x+bx-1*2x-1+...+0*22+1*21+1*20)
И так далее и тому подобное.
Не знаю, считаются ли мои корявые рассуждения доказательством у настоящих математиков, но отсюда во-всяком случае понятно что происходит: в битовом представлении числа самая правая единица превращается в ноль, а все остальное за ней превращается в единицы.
Следующая операция это побитовый И.
Что произойдет с числами А и B когда с ним будет произведена побитовая операция И, если мы знаем, что:
1. B = A - 1, а значит, что
2. До бита с номером Y эти числа совпадают.
3. Бит с номером Y - самая правая единица в числе A, за которым идут нули.
4. Сам бит с номером Y в числе A равен единице, а в B равен нулю и
5. далее в числе A все последующие символы равны нулю, а в B - единице.
Очевидно, что часть числа ДО бита с номером Y останется неизменной, так как a&a=a.
Бит с номером Y будет обнулен и так же будут обнулены все последующие за ним, так как там один из операндов равен нулю.
xx...xx100...00 & xx...xx011...11 =
---------------
xx...xx000...00
Т.е. мы видим, что в результате этой операции самый правый единичный бит в байте превратился в ноль.
Мы сможем повторять эту операцию и результат не будет равен нулю до тех пор, пока последний единичный бит не станет нулевым. Очевидно, что количество итераций и будет равно количеству единиц в числе.
Извините, если мое описание немного сумбурное, буду благодарен за подсказки о том "как правильно".
четверг, 8 апреля 2010 г.

Решение задачи о гномиках в разноцветных шапках
Александр выложил интересную задачу про гномиков.
Не придумал как вставить картинку к нему в каменты, поэтому решение привожу здесь.
Итак, вот схема:
![[Image]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjDce-AhoAOkDEybOlTaggtO0K-xa8MsTphgXcWz7UY-JoQpGOmPN_TmXQUTZ0Nhht4JyLOUyorLZ3txm5gTVKx4vH5gnFnhn3E8OzQw0XZHW_7koLe8j4KGp5vFsGw2LN0er0JjO7h-K-q/s640/xor.gif) В первой строке отмечены номера гномиков (для удобства), во второй их реальное расположение. Гномики смотрят вправо, т.е. номер первый видит всех, последний никого. Далее идут шаги которые гномикам нужно предпринять, чтобы всем спастись (в колонках отмечено кто и что делает).
В первой строке отмечены номера гномиков (для удобства), во второй их реальное расположение. Гномики смотрят вправо, т.е. номер первый видит всех, последний никого. Далее идут шаги которые гномикам нужно предпринять, чтобы всем спастись (в колонках отмечено кто и что делает).
Итак, первый гномик делает операцию последовательного XOR-а. Т.е. он берет 2-го и 3-го гномика и проводит XOR, результат я записал в колонку G (под третьего гномика). После чего он берет результат и XOR-ти с 4-м (результат под 4-го), потом этот результат XOR-ит c 5-ым и т.д. В итоге он получает значение, которое и называет (отмечено желтым). В зависимости от того совпало оно или нет людоед его съедает или нет и тут работает чистая удача.
Но дальше, все уже знают конечный XOR последовательности и могут понять кто они. Например на шаге 3 второй гномик предполагает, что он 0 (отмечено голубым). Исходя из этого он проводит последовательный XOR (шаг 4) и получает в результате 0 (отмечено красным). Поскольку его результат не совпадает с начальным, который посчитал 1-й гномик (желтым) он понимает, что предположение о том, что он 0 было не верным, а значит он 1. И на 5-м шаге говорит: 1. Дальше аналогично третий гномик делает предположение и считает XOR и т.д.
UPD.: (извините, нужно было убегать, потому набросал саму идею, теперь формализую)
Или, говоря строгим языком математики:
Обозначим состояние шапки каждого гномика как X. Тогда состояние шапки n-го гномика будет Xn. Пусть, для определенности, у черных шапок X=1, а для белых X=0.
Так же для определенности, пусть общее количество гномиков равно m.
Вначале первый гномик (который видит всех) должен вычислить "общий XOR" (обозначим его Z) последовательности гномиков по формуле:
Z1=(((X2 XOR X3) XOR X4) XOR X5) ... XOR Xm)
Полученный результат он называет и в зависимости от удачи людоед его съедает, либо нет. (Если Z1 совпало с X1, то, соответственно не съедает). Однако таким образом всем становится известно состояние X1.
Дальше каждый гномик делает предположение о своем состоянии (Xn) и вычисляет собственный "общий XOR" (Zn) по формуле:
Zn=(((Xn-1 XOR Xn) XOR Xn+1) XOR Xn+2) XOR Xn+3) ... XOR Xm)
Если Zn отличается от Z1 то это означает, что предположение гномика о собственном состоянии было ошибочным и он называет противоположное. При совпадении, соответственно, предположение считается верным и называется именно оно.
Таким образом все гномики начиная со 2-го назовут заведомо верные собственные состояния.
Задача решена.
Не придумал как вставить картинку к нему в каменты, поэтому решение привожу здесь.
Итак, вот схема:
![[Image]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjDce-AhoAOkDEybOlTaggtO0K-xa8MsTphgXcWz7UY-JoQpGOmPN_TmXQUTZ0Nhht4JyLOUyorLZ3txm5gTVKx4vH5gnFnhn3E8OzQw0XZHW_7koLe8j4KGp5vFsGw2LN0er0JjO7h-K-q/s1600/xor.gif)
Итак, первый гномик делает операцию последовательного XOR-а. Т.е. он берет 2-го и 3-го гномика и проводит XOR, результат я записал в колонку G (под третьего гномика). После чего он берет результат и XOR-ти с 4-м (результат под 4-го), потом этот результат XOR-ит c 5-ым и т.д. В итоге он получает значение, которое и называет (отмечено желтым). В зависимости от того совпало оно или нет людоед его съедает или нет и тут работает чистая удача.
Но дальше, все уже знают конечный XOR последовательности и могут понять кто они. Например на шаге 3 второй гномик предполагает, что он 0 (отмечено голубым). Исходя из этого он проводит последовательный XOR (шаг 4) и получает в результате 0 (отмечено красным). Поскольку его результат не совпадает с начальным, который посчитал 1-й гномик (желтым) он понимает, что предположение о том, что он 0 было не верным, а значит он 1. И на 5-м шаге говорит: 1. Дальше аналогично третий гномик делает предположение и считает XOR и т.д.
UPD.: (извините, нужно было убегать, потому набросал саму идею, теперь формализую)
Или, говоря строгим языком математики:
Обозначим состояние шапки каждого гномика как X. Тогда состояние шапки n-го гномика будет Xn. Пусть, для определенности, у черных шапок X=1, а для белых X=0.
Так же для определенности, пусть общее количество гномиков равно m.
Вначале первый гномик (который видит всех) должен вычислить "общий XOR" (обозначим его Z) последовательности гномиков по формуле:
Z1=(((X2 XOR X3) XOR X4) XOR X5) ... XOR Xm)
Полученный результат он называет и в зависимости от удачи людоед его съедает, либо нет. (Если Z1 совпало с X1, то, соответственно не съедает). Однако таким образом всем становится известно состояние X1.
Дальше каждый гномик делает предположение о своем состоянии (Xn) и вычисляет собственный "общий XOR" (Zn) по формуле:
Zn=(((Xn-1 XOR Xn) XOR Xn+1) XOR Xn+2) XOR Xn+3) ... XOR Xm)
Если Zn отличается от Z1 то это означает, что предположение гномика о собственном состоянии было ошибочным и он называет противоположное. При совпадении, соответственно, предположение считается верным и называется именно оно.
Таким образом все гномики начиная со 2-го назовут заведомо верные собственные состояния.
Задача решена.
воскресенье, 4 апреля 2010 г.
1Cv8 и gource
Раньше я уже приводил пример, как может быть красиво визуализирована работа с любым проектом при помощи утилиты Gource, если он хранится в системе контроля версий, например svn или git.
Платформа 1С версии восемь имеет собственную систему контроля версий из которой тоже можно получить визуализацию и сейчас я покажу как это можно сделать.
Для начала сохраним лог изменений из хранилища конфигурации. Для этого зайдите в 1С в режиме конфигуртора. Естественно, при входе вы должны будете подключиться к вашему хранилищу:
![[Image]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg6E7qn0MjHJt-uuX8l_rnQQOrPttWgQgzOT2Nl1lpAYpAyHvkFYkJAlCGddhWvrM-tO6zj3BsWxIh7VqTdeQ_DA7mN3FDagTt_Nxim_TTVgfElif7o80hyphenhyphenniOtMsjCmCbTV6-Veg9l_0ZC/s320/1c_save_1.gif)
Теперь выберите в меню пункт "Конфигурация - Хранилище конфигурации - История хранилища":

В открывшемся окне нажмите кнопку "Отчет по истории хранилища" или аналогичный пункт в меню действия:
![[Image]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjBIiwUtKgmOqJ5CHG-vDyk3JzasQxqCcWMuWaiGhqCcSzH3XpI8sUGZrLjXxsSaP6O2hFFbGzKGoH84c5U4pA5dBIs3ZnA2dWnxSe5vDOxPJUHZztRn5q8FlpPIzQKCIvfk472O3GzrfSt/s640/1c_save_3.gif)
Дальше откроется окно настройки лога. Выберите отчет по версиям хранилища, с выводом в текстовый документ и нажмите "Ок":

А полученный текстовый файл сохраните на диск (например с именем conf_report.log):

К сожалению эту операцию нельзя сделать из командной строки, потому что в параметрах отсутствует режим получения изменений по версиям.
Теперь, когда мы сохранили лог изменений его нужно преобразовать в формат понятный gource. Для этого я написал небольшую утилиту на С++, которую назвал log-1c-to-gource.
Скачайте ее и сконвертируйте файл лога:
Теперь осталось только "подсунуть" этот лог gource:
Естественно, вы можете поиграться с параметрами gource как вам нужно и т.д.
А вот несколько скринов, которые получились у меня.
Это скрин с первого комита, когда в хранилище разворачивается вся конфигурация (УТП, если интересно):
 Действительно "взрыв" объектов.
Действительно "взрыв" объектов.
А вот конфигурация уже развернута:
 Здоровенный "одуванчик" слева это документы (с формами и пр.). Их действительно много.
Здоровенный "одуванчик" слева это документы (с формами и пр.). Их действительно много.
И вот работа с некоторыми объектами (я предварительно почистил лог, убрав из него первый комит и теперь огромное дерево не строится):

К сожалению у меня не нашлось хранилища с длиной историей, чтобы записать красивое видео. Если у кого-то такое есть, было бы интересно посмотреть. К тому-же есть несколько идей о том, как можно подправить конвертер, но нужно смотреть как он ведет себя на визуализации больших и долгих проектов. Так что буду благодарен за ваши логи.
Эта статья на Инфостарт
Платформа 1С версии восемь имеет собственную систему контроля версий из которой тоже можно получить визуализацию и сейчас я покажу как это можно сделать.
Для начала сохраним лог изменений из хранилища конфигурации. Для этого зайдите в 1С в режиме конфигуртора. Естественно, при входе вы должны будете подключиться к вашему хранилищу:
![[Image]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg6E7qn0MjHJt-uuX8l_rnQQOrPttWgQgzOT2Nl1lpAYpAyHvkFYkJAlCGddhWvrM-tO6zj3BsWxIh7VqTdeQ_DA7mN3FDagTt_Nxim_TTVgfElif7o80hyphenhyphenniOtMsjCmCbTV6-Veg9l_0ZC/s1600/1c_save_1.gif)
Теперь выберите в меню пункт "Конфигурация - Хранилище конфигурации - История хранилища":

В открывшемся окне нажмите кнопку "Отчет по истории хранилища" или аналогичный пункт в меню действия:
![[Image]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjBIiwUtKgmOqJ5CHG-vDyk3JzasQxqCcWMuWaiGhqCcSzH3XpI8sUGZrLjXxsSaP6O2hFFbGzKGoH84c5U4pA5dBIs3ZnA2dWnxSe5vDOxPJUHZztRn5q8FlpPIzQKCIvfk472O3GzrfSt/s1600/1c_save_3.gif)
Дальше откроется окно настройки лога. Выберите отчет по версиям хранилища, с выводом в текстовый документ и нажмите "Ок":

А полученный текстовый файл сохраните на диск (например с именем conf_report.log):

К сожалению эту операцию нельзя сделать из командной строки, потому что в параметрах отсутствует режим получения изменений по версиям.
Теперь, когда мы сохранили лог изменений его нужно преобразовать в формат понятный gource. Для этого я написал небольшую утилиту на С++, которую назвал log-1c-to-gource.
Скачайте ее и сконвертируйте файл лога:
log-1c-to-gource.exe conf_report.log conf_report_gource.log
Теперь осталось только "подсунуть" этот лог gource:
gource.exe --log-format custom conf_report_gource.log
Естественно, вы можете поиграться с параметрами gource как вам нужно и т.д.
А вот несколько скринов, которые получились у меня.
Это скрин с первого комита, когда в хранилище разворачивается вся конфигурация (УТП, если интересно):

А вот конфигурация уже развернута:

И вот работа с некоторыми объектами (я предварительно почистил лог, убрав из него первый комит и теперь огромное дерево не строится):
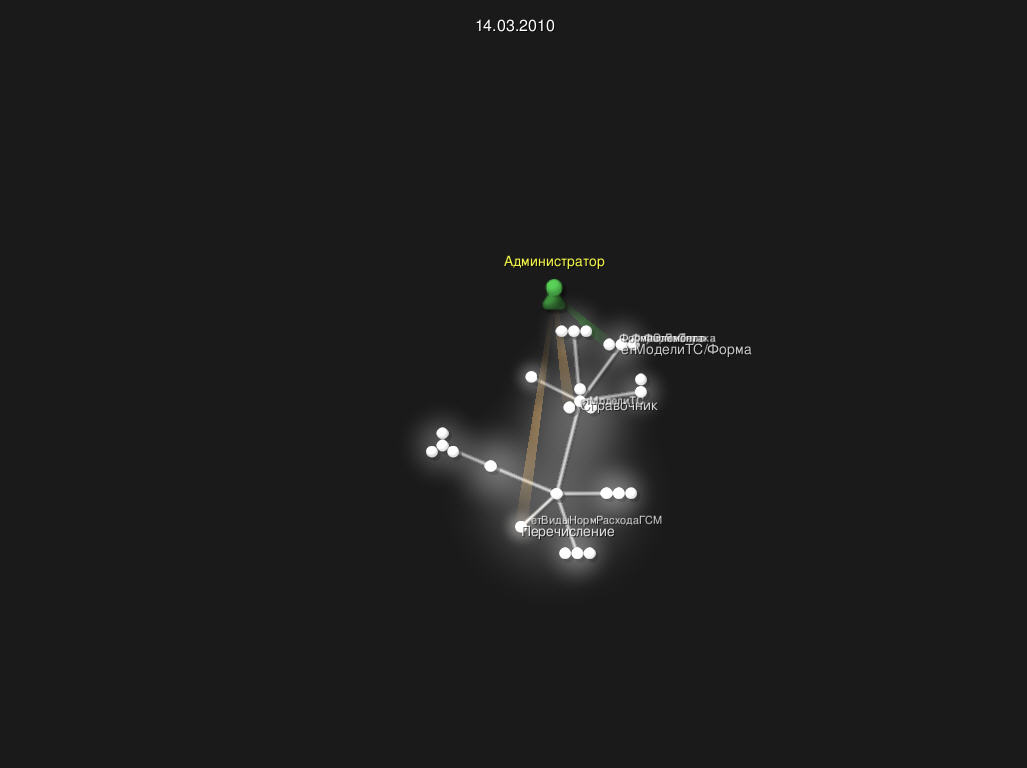
К сожалению у меня не нашлось хранилища с длиной историей, чтобы записать красивое видео. Если у кого-то такое есть, было бы интересно посмотреть. К тому-же есть несколько идей о том, как можно подправить конвертер, но нужно смотреть как он ведет себя на визуализации больших и долгих проектов. Так что буду благодарен за ваши логи.
Эта статья на Инфостарт
четверг, 1 апреля 2010 г.
Первоапрельское мироздание и его чувство юмора
Сегодня мне снилось, что меня рекрутили в GameDev и предлагали вдвое больше того, что я получаю сейчас.
Подписаться на:
Сообщения (Atom)